The Hypertext Transfer Protocol (HTTP) is the foundation of the World Wide Web, and is used to load web pages using hypertext links. HTTP is an application layer protocol designed to transfer information between networked devices and runs on top of other layers of the network protocol stack. A typical flow over HTTP involves a client machine making a request to a server, which then sends a response message.
One common use of HTTP is seo, or search engine optimization. Seo is the process of optimizing a website for Google’s search engine results pages (SERPs). A 301 redirect is a seo technique used to tell Google that a page has been permanently moved to a new location. The 301 redirect sends a server response code of “301 Moved Permanently” to the Google bot, which then updates its index accordingly.
Another common use of HTTP is loading web pages. When you enter a URL into your browser, your browser makes an HTTP request to the server that hosts the website. The server then sends back an HTTP response, which includes the HTML code for the requested page. Your browser then renders the page using the HTML code.
HTTP is an essential part of the World Wide Web, and is
HTTP is designed to permit intermediate network elements to improve or enable communications between clients and servers.
What is a HTTP status code?
When you type a URL into your web browser, your computer sends an HTTP request to the server hosting the website. The server then responds with an HTTP status code, which tells your browser how to handle the request. There are four main categories of HTTP status codes:
– 100-199: Informational – These status codes indicate that the server has received and is processing the request.
– 200-299: Success – These status codes indicate that the request was successful and that the requested resource has been sent back to the browser.
– 300-399: Redirection – These status codes indicate that the browser needs to take additional action in order to complete the request. For example, a 301 redirect code means that the requested resource has been permanently moved to a new location.
– 400-499: Client Error – These status codes indicate that there was an error with the request itself, such as a 404 error code meaning that the requested resource could not be found.
– 500-599: Server Error – These status codes indicate that there was an error on the server side while trying to process the request.
Knowing which HTTP status code is returned for a given request can be helpful for debugging purposes and can also impact SEO;
What are HTTP response headers?
When you type a URL into your web browser, your browser sends an HTTP request to the server that hosts the website. This request includes a number of headers that specify information about the request, such as the type of request (GET or POST), the desired format for the response (e.g., HTML, XML, or JSON), and various other bits of information. The server then responds with its own HTTP headers, which include a status code that indicates whether or not the request was successful (e.g., 200 for success or 404 for not found). The server may also include other headers, such as seo information or a 301 redirect. Understanding HTTP request headers is important for troubleshooting website errors and for optimizing website performance.
What is an HTTP response body?
When a user enters a URL into their web browser, the browser sends an HTTP request to the server that hosts the website. The server then looks up the requested resources and sends an HTTP response back to the browser. The response includes a status code that indicates whether or not the request was successful, as well as a response body containing the requested resources. In some cases, the response body may also contain additional information, such as SEO metadata or 301 redirects. By understanding what’s in an HTTP response body, web developers can troubleshoot errors and optimize their website’s performance.
What is an HTTP response?
When you type a URL into your browser and hit enter, your computer sends an HTTP request to the server that houses the website you’re trying to access. The server then responds with an HTTP response, which includes the website’s content as well as some additional information. This information can include the server’s response code, which indicates whether or not the request was successful, as well as any seo keywords that have been assigned to the website. In some cases, the server may also send a 301 redirect, which tells the browser to go to a different URL. The HTTP response is an essential part of how the internet works, and it plays a vital role in SEO and website design.
HTTP/1.x vs HTTP/2
| Differentiator | HTTP/1.0 | HTTP/1.1 | HTTP/2 |
| Year | 1991 | 1997 | 2015 |
| Key Features | For every TCP connection there is only one request and one response.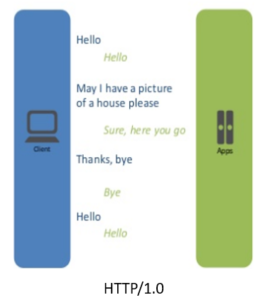 |
It supports connection reuse i.e. for every TCP connection there could be multiple requests and responses, and pipelining where the client can request several resources from the server at once. However, pipelining was hard to implement due to issues such as head-of-line blocking and was not a feasible solution.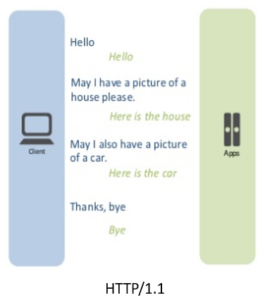 |
Uses multiplexing, where over a single TCP connection resources to be delivered are interleaved and arrive at the client almost at the same time. It is done using streams which can be prioritized, can have dependencies and individual flow control. It also provides a feature called server push that allows the server to send data that the client will need but has not yet requested.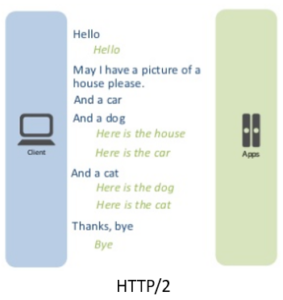 |
| Status Code | Can define 16 status codes; the error prompt is not specific enough. | Introduces a warning header field to carry additional information about the status of a message. Can define 24 status codes, error reporting is quicker and more efficient. | Underlying semantics of HTTP such as headers, status codes remains the same. |
| Authentication Mechanism | Uses basic authentication scheme which is unsafe since username and passwords are transmitted in clear text or base64 encoded. | It is relatively secure since it uses digest authentication, NTLM authentication. | Security concerns from previous versions will continue to be seen in HTTP/2. However, it is better equipped to deal with them due to new TLS features like connection error of type Inadequate_Security. |
| Caching | Provides support for caching via the If-Modified-Since header. | Expands on the caching support by using additional headers like cache-control, conditional headers like If-Match and by using entity tags. | HTTP/2 does not change much in terms of caching. With the server push feature if the client finds the resources are already present in the cache, it can cancel the pushed stream. |
| Web Traffic | HTTP/1.1 provides faster delivery of web pages and reduces web traffic as compared to HTTP/1.0. However, TCP starts slowly and with domain sharding (resources can be downloaded simultaneously by using multiple domains), connection reuse and pipelining, there is an increased risk of network congestion. | HTTP/2 utilizes multiplexing and server push to effectively reduce the page load time by a greater margin along with being less sensitive to network delays. | |
HTTP Related Protocols
IMAP
The Internet Message Access Protocol, version 4rev1 (IMAP4) is an email client that allows you to access and manipulate messages on your server. The most important feature of this protocol are mailboxes – remote storage areas for all those little pieces of information we send one another via e-mail! With it comes some very useful perks like being able sync up again if needed without having any connection at all; even when offline…
MIME
RFC 822 defines a message representation protocol which specifies considerable detail about message headers, but which leaves the message content, or message body, as flat ASCII text. MIME redefines the format of message bodies to allow multi-part textual and non-textual message bodies to be represented and exchanged without loss of information.
Source: https://www.w3.org/Protocols/RelevantProtocols.html
File Transfer Protocol (FTP)
The file transfer protocol currently most used for accessing fairly stable public information over a wide area is “Anonymous FTP”. This means the use of the internet File Transfer Protocol without authentication. As the WWW project currently operates for the sake of public information, anonymous FTP is quite appropriate, and WWW can pick up any information provided by anonymous FTP.
Source: https://www.w3.org/Protocols/RelevantProtocols.html